最近更新: 2020-6-8 upds。
DML-数据操作语言
插入:insert
修改:update
删除:delete
1.插入语句
方式一:经典的插入
语法:insert into 表名(列名,…) values(值1,…);
1.插入的值的类型要与列的类型一致或兼容
1 | INSERT INTO beauty(id,NAME,sex,borndate,phone,photo,boyfriend_id) |
2.不可以为null的列必须插入值。可以为null的列如何插入值?
方式一:令其为null
1 | INSERT INTO beauty(id,NAME,sex,borndate,phone,photo,boyfriend_id) |
#方式二:可以为空的,不写就好
1 | INSERT INTO beauty(id,NAME,sex,phone) |
3.列的顺序是可以调换,但是value一定要一一对应
1 | INSERT INTO beauty(NAME,sex,id,phone) |
4.列数和值的个数必须一致
1 | INSERT INTO beauty(NAME,sex,id,phone) |
5.可以省略列名,默认所有列,而且列的顺序和表中列的顺序一致,可以的
1 | INSERT INTO beauty |
方式二:
语法:
insert into 表名
set 列名=值,列名=值,…
1 | INSERT INTO beauty |
两种方式大pk :
1、方式一支持插入多行,方式二不支持
1 | INSERT INTO beauty |
2、方式一支持子查询,方式二不支持
先执行SELECT 26,'宋茜','11809866';查出来的结果在进行insert
1 | INSERT INTO beauty(id,NAME,phone) |
先从boys中查询出结果,然后进行插入,
1 | INSERT INTO beauty(id,NAME,phone) |
2. 修改语句
1.修改单表的记录★
语法:
update 表名
set 列=新值,列=新值,…
where 筛选条件;
2.修改多表的记录【补充】
语法:
sql92语法:
update 表1 别名,表2 别名
set 列=值,…
where 连接条件
and 筛选条件;
sql99语法:
update 表1 别名
inner|left|right join 表2 别名
on 连接条件
set 列=值,…
where 筛选条件;
1.修改单表的记录
案例1:修改beauty表中姓唐的女神的电话为13899888899
1 | UPDATE beauty SET phone = '13899888899' |
案例2:修改boys表中id好为2的名称为张飞,魅力值 10
1 | UPDATE boys SET boyname='张飞',usercp=10 |
2.修改多表的记录
#案例 1:修改张无忌的女朋友的手机号为114
1 | UPDATE boys bo |
#案例2:修改没有男朋友的女神的男朋友编号都为2号
1 | UPDATE boys bo |
3. 删除语句
方式一:delete
语法:
1、单表的删除【★】
delete from 表名 where 筛选条件
2、多表的删除【补充】
sql92语法:
delete 表1的别名,表2的别名
from 表1 别名,表2 别名
where 连接条件
and 筛选条件;
sql99语法:
delete 表1的别名,表2的别名
from 表1 别名
inner|left|right join 表2 别名 on 连接条件
where 筛选条件;
方式二:truncate
语法:truncate table 表名;
方式一:delete
1.单表的删除
案例:删除手机号以9结尾的女神信息
1 | DELETE FROM beauty WHERE phone LIKE '%9'; |
2.多表的删除
案例:删除张无忌的女朋友的信息
1 | DELETE b |
案例:删除黄晓明的信息以及他女朋友的信息
1 | DELETE b,bo |
方式二:truncate语句
案例:将魅力值>100的男神信息删除,其实是做不到的,因为不可能在后面加上where,所以truncate也被叫做清空数据
1 | TRUNCATE TABLE boys ; |
delete pk truncate【面试题】
1.delete 可以加where 条件,truncate不能加
2.truncate删除,效率高一丢丢
3.假如要删除的表中有自增长列(加入数据自己增长),如果用delete删除后,再插入数据,自增长列的值从断点开始,
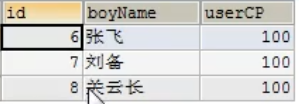

而truncate删除后,再插入数据,自增长列的值从1开始。

4.truncate删除没有返回值,delete删除有返回值,告诉你几行被删除了
5.truncate删除不能回滚,delete删除可以回滚.
DDL—数据定义语言(库和表的管理 )
库和表的管理
一、库的管理
创建、修改、删除
二、表的管理
创建、修改、删除
创建: create
修改: alter
删除: drop
一、库的管理
1、库的创建
语法:
create database [if not exists]库名;
案例:创建库Books
1 | CREATE DATABASE IF NOT EXISTS books ; |
2、库的修改
1 | RENAME DATABASE books TO 新库名; |
3.更改库的字符集
1 | ALTER DATABASE books CHARACTER SET gbk; |
4、库的删除
1 | DROP DATABASE IF EXISTS books; |
二、表的管理
1.表的创建 ★
语法:
create table 表名(
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
…
列名 列的类型【(长度) 约束】
)
- 案例:创建表Book
1 | CREATE TABLE book( |
1 | DESC book; |

- 案例:创建表author
1 | CREATE TABLE IF NOT EXISTS author( |
DESC author;

2. 表的修改
语法
alter table 表名 add|drop|modify|change column 列名 【列类型 约束】;
①修改列名
1 | ALTER TABLE book CHANGE COLUMN publishdate pubDate DATETIME; |
②修改列的类型或约束
1 | ALTER TABLE book MODIFY COLUMN pubdate TIMESTAMP; |
③添加新列
1 | ALTER TABLE author ADD COLUMN annual DOUBLE; |
④删除列
1 | ALTER TABLE book_author DROP COLUMN annual; |
⑤修改表名
1 | ALTER TABLE author RENAME TO book_author; |
表的删除
3.表的删除
1 | DROP TABLE IF EXISTS book_author; |
通用的写法:
1 | DROP DATABASE IF EXISTS 旧库名; |
4.表的复制
先创建一个表
1 | INSERT INTO author VALUES |
1 | SELECT * FROM Author; |
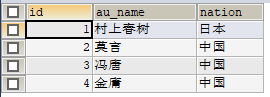
1.仅仅复制表的结构,没有数据
1 | CREATE TABLE copy LIKE author; |
2.复制表的结构+数据
1 | CREATE TABLE copy2 |
只复制部分数据
1 | CREATE TABLE copy3 |
仅仅复制某些字段,因为条件不满足直接是空列
1 | CREATE TABLE copy4 |
5.案例讲解
- 创建表dept1
id INT(7)
NAME VARCHAR(25)
1 | USE test; |
- 将表departments中的数据插入新表dept2中,可以跨库去赋值表结构
1 | CREATE TABLE dept2 |
- 创建表emp5
id INT(7)
First_name VARCHAR (25)
Last_name VARCHAR(25)
Dept_id INT(7)
1 | CREATE TABLE emp5( |
- 将列Last_name的长度增加到50
1 | ALTER TABLE emp5 MODIFY COLUMN last_name VARCHAR(50); |
- 根据表employees创建employees2
1 | CREATE TABLE employees2 LIKE myemployees.employees; |
- 删除表emp5
1 | DROP TABLE IF EXISTS emp5; |
- 将表employees2重命名为emp5
1 | ALTER TABLE employees2 RENAME TO emp5; |
- 在表dept和emp5中添加新列test_column,并检查所作的操作
1 | ALTER TABLE emp5 ADD COLUMN test_column INT; |
- 直接删除表emp5中的列 dept_id
1 | DESC emp5; |
三、常见的数据类型
数值型:
整型
特点:
① 如果不设置无符号还是有符号,默认是有符号,如果想设置无符号,需要添加unsigned关键字
② 如果插入的数值超出了整型的范围,会报out of range异常,并且插入临界值
③ 如果不设置长度,会有默认的长度
长度代表了显示的最大宽度,如果不够会用0在左边填充,但必须搭配zerofill使用!
小数:
分类:1.浮点型float(M,D),double(M,D)
2.定点型 dec(M,D),decimal(M,D)
特点:
①
M:整数部位+小数部位
D:小数部位
如果超过范围,则插入临界值
②
M和D都可以省略
如果是decimal,则M默认为10,D默认为0
如果是float和double,则会根据插入的数值的精度来决定精度
③定点型的精确度较高,如果要求插入数值的精度较高如货币运算等则考虑使用字符型:
较短的文本:char、varchar
较长的文本:text、blob(较长的二进制数据)
字符型
较短的文本:char,varchar
其他:
binary和varbinary用于保存较短的二进制
enum用于保存枚举
set用于保存集合
较长的文本:
text
blob(较大的二进制)
特点:
| 写法 | M的意思 | 特点 | 空间的耗费 | 效率 | |
|---|---|---|---|---|---|
| char | char(M) | 最大的字符数,可以省略,默认为1 | 固定长度 | 比较耗费 | 高 |
| varchar | varchar(M) | 最大的字符数,不可以省略 | 可变长度 | 比较节省 | 低 |
枚举:列表中只可以选择一个插入
1 | CREATE TABLE tab_char( |
1 | INSERT INTO tab_char VALUES('a'); |
1 | SELECT * FROM tab_char; |
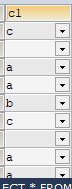
因为A和m超出类型所以就显示为空
Set集合类型
和Enum类似,里面只可以保存0~64个成员,区别:Set一次可以选取多个成员,而Enum只能选一个根据成员个数不同
因为A和m超出类型所以就显示为空
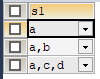
1 | CREATE TABLE tab_set( |
1 | INSERT INTO tab_set VALUES('a'); |
四、常见约束
含义:一种限制,用于限制表中的数据,为了保证表中的数据的准确和可靠性
分类:六大约束
NOT NULL:非空,用于保证该字段的值不能为空
比如姓名、学号等,就像挂星星的必选项
DEFAULT:默认,用于保证该字段有默认值
比如性别,默认为男
PRIMARY KEY:主键,用于保证该字段的值具有唯一性,并且非空
比如学号、员工编号等
UNIQUE:唯一,用于保证该字段的值具有唯一性,可以为空
比如座位号
CHECK:检查约束【mysql中不支持】
比如年龄、性别
FOREIGN KEY:外键,用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值
在从表中添加外键约束,用于引用主表中某列的值
例如:专业id就必须受到专业表的约束,必须在此专业表的范围内,部门编号、工种编号等
添加约束的时机:
1.创建表时
2.修改表时
约束的添加分类:自我感觉列级约束更像是人话,而表级约束更像是函数
列级约束:
六大约束语法上都支持,但外键约束没有效果
表级约束:
除了非空、默认,其他的都支持
1 | CREATE TABLE 表名( |
主键和唯一的大对比:
保证唯一性 是否允许为空 一个表中可以有多少个 是否允许组合
主键 √ × 至多有1个 √, 但不推荐
唯一 √ √ 可以有多个 √, 但不推荐
外键:
1、要求在从表设置外键关系
2、从表的外键列的类型和主表的关联列的类型要求一致或兼容,名称无要求
3、主表的关联列必须是一个key(一般是主键或唯一)
4、插入数据时,先插入主表,再插入从表
删除数据时,先删除从表,再删除主表
1. 添加列级约束
语法:
直接在字段名和类型后面追加 约束类型即可。可以添加多个列级约束
只支持:默认、非空、主键、唯一
1 | USE students; |
1 | CREATE TABLE major( |
查看stuinfo中的所有索引,包括主键、外键、唯一
1 | SHOW INDEX FROM stuinfo; |

2.添加表级约束
语法:在各个字段的最下面
【constraint 约束名】 约束类型(字段名)
1 | DROP TABLE IF EXISTS stuinfo; |

可以去掉前面的设置名称:
1 | DROP TABLE IF EXISTS stuinfo; |
通用的写法:
1 | CREATE TABLE IF NOT EXISTS stuinfo( |
3. 主键和唯一的大对比:
| 保证唯一性 | 是否允许为空 | 一个表中可以有多少个 | 是否允许组合 | |
|---|---|---|---|---|
| 主键 | √ | × | 至多有1个 | √,但不推荐(多个列组合成一个) |
| 唯一键 | √ | √ | 可以有多个 | √,但不推荐 |
外键:
1、要求在从表设置外键关系
2、从表的外键列的类型和主表(引用的表)的关联列的类型要求一致或兼容,名称无要求
3、主表的关联列必须是一个key(一般是主键 primary key或唯一 unique)
4、插入数据时,先插入主表,再插入从表(有了专业在招学生)
删除数据时,先删除从表,再删除主表
4. 修改表时添加约束
1、添加列级约束
1 | alter table 表名 modify column 字段名 字段类型 新约束; |
案例:首先创建表
1 | DROP TABLE IF EXISTS stuinfo; |
- 添加非空约束,使得
1 | ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NOT NULL; |
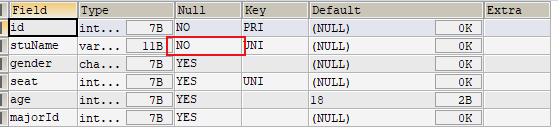
2、添加表级约束
1 | alter table 表名 add 【constraint 约束名】 约束类型(字段名) 【外键的引用】; |
- 添加默认约束
1 | ALTER TABLE stuinfo MODIFY COLUMN age INT DEFAULT 18; |
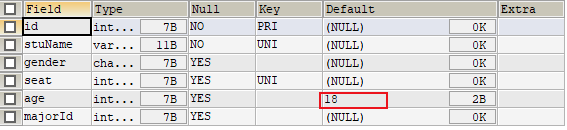
3.添加主键
①列级约束(把id添加为主键)
1 | ALTER TABLE stuinfo MODIFY COLUMN id INT PRIMARY KEY; |
②表级约束(把id添加为主键)
1 | ALTER TABLE stuinfo ADD PRIMARY KEY(id); |
4.添加唯一
①列级约束
1 | ALTER TABLE stuinfo MODIFY COLUMN seat INT UNIQUE; |
②表级约束
1 | ALTER TABLE stuinfo ADD UNIQUE(seat); |
#5.添加外键
1 | ALTER TABLE stuinfo ADD CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id); |
5、修改表时删除约束
1.删除非空约束
1 | ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NULL; |
#2.删除默认约束,相当于又加了一遍的感觉
1 | ALTER TABLE stuinfo MODIFY COLUMN age INT ; |
#3.删除主键
1 | ALTER TABLE stuinfo DROP PRIMARY KEY; |
#4.删除唯一
1 | ALTER TABLE stuinfo DROP INDEX seat; |
#5.删除外键
1 | ALTER TABLE stuinfo DROP FOREIGN KEY fk_stuinfo_major; |
五、标识列
又称为自增长列
含义:可以不用手动的插入值,系统提供默认的序列值
特点:
1、标识列必须和主键搭配吗?不一定,但要求是一个key
2、一个表可以有几个标识列?至多一个!
3、标识列的类型只能是数值型,一般是int
4、标识列可以通过 SET auto_increment_increment=3;设置步长
可以通过 手动插入值,设置起始值
一、创建表时设置标识列,通过auto_increment可以实现自增长
1 | DROP TABLE IF EXISTS tab_identity; |
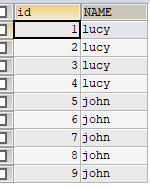
设置步长和起始值(MySQL不支持)
1 | SHOW VARIABLES LIKE '%auto_increment%'; |
设置步长值为3:
1 | SET auto_increment_increment=3; |
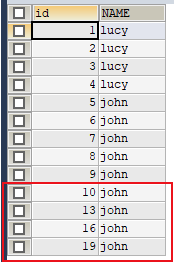
$$ —- \mathcal{End} —- $$

