最近更新: 2020-6-6 upds。
数据库基础—DQL
基础概念
数据库语言分类
DQL(Data Query Language):数据查询语言 select
DML(Data Manipulate Language):数据操作语言 insert 、update、delete
DDL(Data Define Languge):数据定义语言 create、drop、alter
TCL(Transaction Control Language):事务控制语言 commit、rollback
UTF-8和gb2312的区别
#utf8默认一个字母占一个字节,一个汉字占3个字节。
1.基础查询&条件查询
1.筛选条件的分类
1、简单条件运算符
>, < = <> != >= <= <=>安全等于
2、逻辑运算符
等价于&& and
等价于|| or
等价于! not
3、模糊查询
like:一般搭配通配符使用,可以判断字符型或数值型
通配符:%任意多个字符,_任意单个字符
between and
in
- 案例:查询部门编号不等于90号的员工名和部门编号
1 | select |
- 案例:查询工资z在10000到20000之间的员工名、工资以及奖金
1 | SELECT |
- 案例:查询部门编号不是在90到110之间,或者工资高于15000的员工信息
1 | SELECT |
案例:查询员工名中包含字符a的员工信息
1
2
3
4
5
6select
*
from
employees
where
last_name like '%a%';案例:查询员工名中第三个字符为e,第五个字符为a的员工名和工资
1 | SELECT |
- 案例:查询员工名中第二个字符为_的员工名
可以使用/作为转义字符;也可以使用任意转义字符如前面的$,这里使用escape目的是使得$没有实际意义;
1 | SELECT |
between and
包含边界值
- 案例1:查询员工编号在100到120之间的员工信息
1 | SELECT |
1 | SELECT |
in
in列表的值类型必须一致或兼容
in列表中不支持通配符
- 案例:查询员工的工种编号是 IT_PROG、AD_VP、AD_PRES中的一个员工名和工种编号
1 | SELECT |
1 | SELECT |
is null
=或<>不能用于判断null值
is null或is not null 可以判断null值,这个is not就是和null搭配的不可以用于其他内容
- 案例1:查询没有奖金的员工名和奖金率
1 | SELECT |
1 | SELECT |
- 案例2:查询工资为17000的员工名和奖金率,注意:不可以用IS而是用17000
1 | SELECT |
is null /is not null:用于判断null值
is null PK <=>
IS NULL:仅仅可以判断NULL值,可读性较高,建议使用
<=> :既可以判断NULL值,又可以判断普通的数值,可读性较低
| 普通类型的数值 | null值 | 可读性 | |
|---|---|---|---|
| is null | × | √ | √ |
| <=> | √ | √ | × |
- 案例:查询工号为AD_VP的员工的姓名和部门的号的年薪
1 | SELECT |
- 案例:查询没有奖金,且工资小于18000的salary,last_name
1 | SELECT |
- 案例:查询employees表中,job_id不为‘AD_VP’或者工资为12000的员工信息
1 | SELECT |
4、快速查询
- 查看部门
1 | DESC departments; |
- 查看部门department表中涉及到了哪些编号,DISTINCT具有去重的功能
1 | SELECT DISTINCT location_id |
经典面试题:
1 | SELECT * FROM employees |
1 | SELECT*FROM employees; |
是不一样的,上面的会把null的包含,如果将下面的AND变为or就一样了
2.排序查询
一、语法
select 查询列表
from 表
where 筛选条件
order by 排序列表 【asc/desc】
1、asc :升序,如果不写默认升序
desc:降序
2、排序列表 支持 单个字段、多个字段、函数、表达式、别名
3、order by的位置一般放在查询语句的最后(除limit语句之外)
1. 按单个字段排序
- 案例:查询工资薪水按照降序排列
1 | SELECT * FROM employees |
2. 添加筛选条件再排序
- 案例:查询部门编号>=90的员工信息,并按员工编号降序(入职的先后顺序)
1 | SELECT * |
3. 按表达式排序
- 案例:查询员工信息 按年薪降序
因为1+null等于null,所以需要处理一下,IFNULL(commission_pct,0)),如果不是null就加上奖金
1 | SELECT *,salary*12*(1+IFNULL(commission_pct,0)) |

4.按函数排序
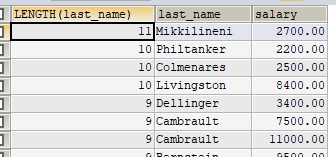
- 案例:查询员工名,并且按名字的长度降序
1 | SELECT LENGTH(last_name),last_name ,salary |
5、按别名排序
- 案例:查询员工信息 按年薪升序
别名就是年薪,order by后面也是支持别名
1 | SELECT *,salary*12*(1+IFNULL(commission_pct,0)) 年薪 |

6、按多个字段排序
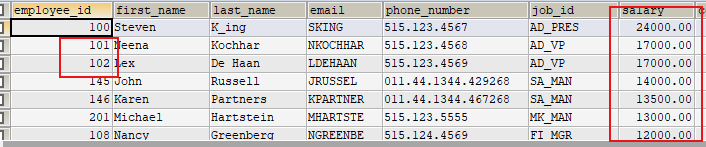
- 案例:查询员工信息,要求先按工资降序,再按employee_id升序
1 | SELECT * |
先按照工资进行排序,然后按照员工编号排序(就是当有salary一样的时候,按照employee_id排序)
3.常见函数
1. 字符函数
2. 数字函数
3. 日期函数
4. 流程控制函数
聚合函数:将一列数据作为一个整体,进行纵向的计算。
count:计算个数
- 一般选择非空的列:主键
- count(*)
max:计算最大值
min:计算最小值
sum:计算和
avg:计算平均值
* 注意:聚合函数的计算,排除null值。 解决方案: 1. 选择不包含非空的列进行计算 2. IFNULL函数
4. 分组查询
一、语法
select 分组函数,分组后的字段
from 表
【where 筛选条件】例如:奖金不为空
group by 分组的字段 例如:按照工种分
【having 分组后的筛选】例如:员工个数大于5
【order by 排序列表】例如:按照薪水降序
| 使用关键字 | 筛选的表 | 位置 | |
|---|---|---|---|
| 分组前筛选 | where | 原始表 | group by的前面 |
| 分组后筛选 | having | 分组后结果 | group by的后面 |
- 案例1:查询每个工种的员工平均工资
所以是按照每一种job_id 查询
1 | SELECT AVG(salary),job_id |
- 案例2:查询每个位置的部门个数
1 | SELECT COUNT(*),location_id |
1. 可以实现分组前的筛选
- 案例1:查询邮箱中包含a字符的 每个部门的最高工资(只在email中有a的中筛选)
1 | SELECT MAX(salary),department_id |
案例2:查询有奖金的每个领导手下员工的平均工资
1 | SELECT AVG(salary),manager_id |
2. 分组后筛选
案例1:查询哪个部门的员工个数>5
①查询每个部门的员工个数
1 | SELECT COUNT(*),department_id |
#② 筛选刚才①结果
1 | SELECT COUNT(*),department_id |
- 案例2:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
1 | SELECT job_id,MAX(salary) |
- 案例3:领导编号>102的每个领导手下的最低工资大于5000的领导编号和最低工资
1 | SELECT manager_id,MIN(salary) |
3. 添加排序
- 案例:每个工种有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序
1 | SELECT job_id,MAX(salary) m |
4. 按多个字段分组
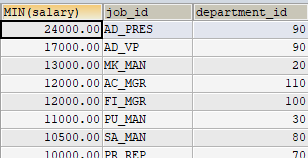
#案例:查询每个工种每个部门的最低工资,并按最低工资降序
1 | SELECT MIN(salary),job_id,department_id |
5. 连接查询
一、含义
当查询中涉及到了多个表的字段,需要使用多表连接
select 字段1,字段2
from 表1,表2,…;
笛卡尔乘积:当查询多个表时,没有添加有效的连接条件,导致多个表所有行实现完全连接
如何解决:添加有效的连接条件
按年代分类:
sql92标准:仅仅支持内连接(等值、非等值、和自连接)
sql99标准【推荐】:支持内连接+外连接(左外和右外)+交叉连接
按功能分类:
内连接:等值连接,非等值连接,自连接
外连接: 左外连接,右外连接,全外连接
交叉连接
1. 等值连接
① 多表等值连接的结果为多表的交集部分
②n表连接,至少需要n-1个连接条件
③ 多表的顺序没有要求
④一般需要为表起别名
⑤可以搭配前面介绍的所有子句使用,比如排序、分组、筛选
- 案例1:查询女神名和对应的男神名
1 | SELECT NAME,boyName |
- 案例2:查询员工名和对应的部门名
1 | SELECT last_name,department_name |
1. 为表起别名
①提高语句的简洁度
②区分多个重名的字段
注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定
查询员工名、工种号、工种名
1 | SELECT e.last_name,e.job_id,j.job_title |
2. 两个表的顺序是否可以调换
查询员工名、工种号、工种名
1 | SELECT e.last_name,e.job_id,j.job_title |
3. 可以加筛选
- 案例1:查询有奖金的员工名、部门名
1 | SELECT last_name,department_name,commission_pct |
- 案例2:查询城市名中第二个字符为o的部门名和城市名
1 | SELECT department_name,city |
- 案例3:查询每个城市的部门个数
1 | SELECT COUNT(*) 个数,city |
- 案例4:查询有奖金的每个部门的部门名和部门的领导编号和该部门的最低工资
1 | SELECT department_name,d.`manager_id`,MIN(salary) |
4. 可以加排序
案例:查询每个工种的工种名和员工的个数,并且按员工个数降序
1 | SELECT job_title,COUNT(*) |
5.可以实现三表连接
- 案例:查询员工名、部门名和所在的城市
1 | SELECT last_name,department_name,city |
2. 非等值连接
- 案例1:工的工资级别
1 | SELECT salary,grade_level |
对比sql92的格式:
1 | SELECT salary,grade_level |
- 案例2:资级别的个数>20的个数,并且按工资级别降序
1 | SELECT COUNT(*),grade_level |
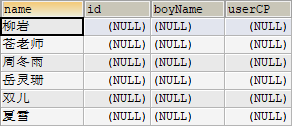
3. 自连接
自己连接自己
- 案例:查询 员工名和上级的名称
1 | SELECT e.employee_id,e.last_name,m.employee_id,m.last_name |

从上表可以看出k_ing的emplyee_id是100,kochhar的manage_id是100,所以kochhar的领导是k_ing,所以结果如下:

4. 外连接
应用场景:用于查询一个表中有,另一个表没有的记录
特点:
1、外连接的查询结果为主表中的所有记录
如果从表中有和它匹配的,则显示匹配的值
如果从表中没有和它匹配的,则显示null
外连接查询结果=内连接结果+主表中有而从表没有的记录
2、左外连接,left join左边的是主表
右外连接,right join右边的是主表
3、左外和右外交换两个表的顺序,可以实现同样的效果
4、全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的
如果仅仅是下面这样查询就只是笛卡尔乘积,出现很多的null
1 | SELECT * FROM beauty; |
你要查询的信息主要在那个表,那个表就是主表。
- 左外连接,可以看出beauty是主表,左外连接了boy表,条件是b.
boyfriend_id= bo.id
1 | SELECT b.name,bo.* |

筛选出没有男朋友的beauty,分别用左外右外连接实现
- 左外连接
1 | SELECT b.name,bo.* |
- 右外连接(只需要修改几处即可)
1 | SELECT b.name,bo.* |
- 案例1:查询哪个部门没有员工
左外(LEFT OUTER JOIN 的左边是主表)
1 | SELECT d.*,e.employee_id |
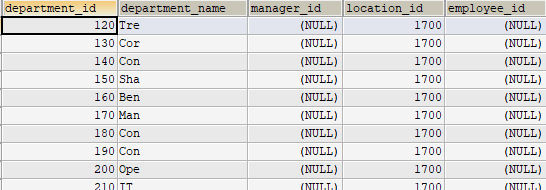
右外
结果同上
1 | SELECT d.*,e.employee_id |
全外
全外就是不分主从表,首先两部分的交集是可以出现的,左外的部分会出现,右外的部分也会出现
全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的
6.子查询
含义:出现在其他语句中的select语句,称为子查询或内查询,外部的查询语句,称为主查询或外查询
特点:
①子查询放在小括号内
②子查询一般放在条件的右侧
③标量子查询,一般搭配着单行操作符使用
> < >= <= = <>
列子查询,一般搭配着多行操作符使用
in、any/some、all
④子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
1.标量子查询
#案例1:谁的工资比 Abel 高?
①查询Abel的工资
1 | SELECT salary |
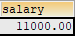
#②查询员工的信息,满足 salary>①结果
1 | SELECT * |

#案例2:返回job_id与141号员工相同,salary比143号员工多的员工 姓名,job_id 和工资
2.列子查询(多行子查询)一列多行
案例:返回其它工种中比job_id为‘IT_PROG’工种任一工资低的员工的员工号、姓名、job_id 以及salary
①查询job_id为‘IT_PROG’部门任一工资
1 | SELECT DISTINCT salary |
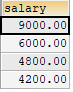
②查询员工号、姓名、job_id 以及salary,salary<(①)的任意一个
1 | SELECT last_name,employee_id,job_id,salary |

3. 行子查询(结果集一行多列或多行多列) 了解
1 | SELECT * |
#①查询最小的员工编号
1 | SELECT MIN(employee_id) |
#②查询最高工资
1 | SELECT MAX(salary) |
#③查询员工信息
1 | SELECT * |
以下几种情况:
select后面
仅仅支持标量子查询
案例:查询每个部门的员工个数,牛逼!牛逼!
1 | SELECT d.*,( |

from后面
将子查询结果充当一张表,要求必须起别名
有时间将这里在补充一下,重新看一下尚硅谷是视频
exists后面(相关子查询)
语法:exists(完整的查询语句) 结果:1或0
1 | SELECT EXISTS(SELECT employee_id FROM employees WHERE salary=300000); |
如果有的话,结果就是1,如果没有的话,结果是0;
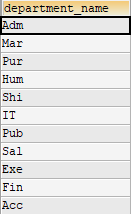
#案例1:查询有员工的部门名#in,两种方式,一种是in一种是exist
1 | SELECT department_name |
7. 分页查询
应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求
语法:
select 查询列表
from 表
【join type join 表2
on 连接条件
where 筛选条件
group by 分组字段
having 分组后的筛选
order by 排序的字段】
limit 【offset,】size;
- 案例1:查询前五条员工信息
1 | SELECT * FROM employees LIMIT 0,5; |

- 案例2:查询第11条——第25条
1 | SELECT * FROM employees LIMIT 10,15; |

8. 联合查询
union 联合 合并:将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
应用场景:
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时
特点:
1、要求多条查询语句的查询列数是一致的!
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、union关键字默认去重,如果使用union all 可以包含重复项
- 案例:查询部门编号>90或邮箱包含a的员工信息
1 | SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;; |
- 案例:查询中国用户中男性的信息以及外国用户中年男性的用户信息
1 | SELECT id,cname FROM t_ca WHERE csex='男' |
$$ —- \mathcal{End} —- $$

