最近更新: 2020-6-6 upds。
常见约束
含义:一种限制,用于限制表中的数据,为了保证表中的数据的准确和可靠性
分类:六大约束
NOT NULL:非空,用于保证该字段的值不能为空
比如姓名、学号等
DEFAULT:默认,用于保证该字段有默认值
比如性别
PRIMARY KEY:主键,用于保证该字段的值具有唯一性,并且非空
比如学号、员工编号等
UNIQUE:唯一,用于保证该字段的值具有唯一性,可以为空
比如座位号
CHECK:检查约束【mysql中不支持】
比如年龄、性别
FOREIGN KEY:外键,用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值
在从表添加外键约束,用于引用主表中某列的值
比如学生表的专业编号,员工表的部门编号,员工表的工种编号
约束的添加分类:
列级约束:
六大约束语法上都支持,但外键约束没有效果
表级约束:
除了非空、默认,其他的都支持
保证唯一性 是否允许为空 一个表中可以有多少个 是否允许组合
主键 √ × 至多有1个 √, 但不推荐
唯一 √ √ 可以有多个 √, 但不推荐
外键:
1、要求在从表设置外键关系
2、从表的外键列的类型和主表的关联列的类型要求一致或兼容,名称无要求
3、主表的关联列必须是一个key(一般是主键或唯一)
4、插入数据时,先插入主表,再插入从表
删除数据时,先删除从表,再删除主表
一、创建表时添加约束
1.添加列级约束
语法:
直接在字段名和类型后面追加 约束类型即可。
只支持:默认、非空、主键、唯一
1 | USE students; |
1 | CREATE TABLE major( |
查看stuinfo中的所有索引,包括主键、外键、唯一
1 | SHOW INDEX FROM stuinfo; |

2.添加表级约束
语法:在各个字段的最下面
【constraint 约束名】 约束类型(字段名)
1 | DROP TABLE IF EXISTS stuinfo; |

#通用的写法:
1 | CREATE TABLE IF NOT EXISTS stuinfo( |
二、修改表时添加约束
1、添加列级约束
alter table 表名 modify column 字段名 字段类型 新约束;
2、添加表级约束
alter table 表名 add 【constraint 约束名】 约束类型(字段名) 【外键的引用】;
1 | DROP TABLE IF EXISTS stuinfo; |
1.添加非空约束
1 | ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NOT NULL; |
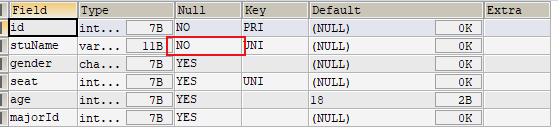
2.添加默认约束
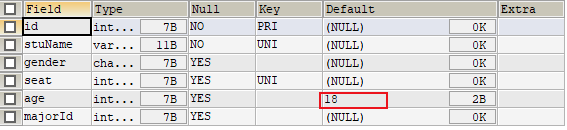
1 | ALTER TABLE stuinfo MODIFY COLUMN age INT DEFAULT 18; |
3.添加主键
①列级约束(把id添加为主键)
1 | ALTER TABLE stuinfo MODIFY COLUMN id INT PRIMARY KEY; |
②表级约束(把id添加为主键)
1 | ALTER TABLE stuinfo ADD PRIMARY KEY(id); |
4.添加唯一
#①列级约束
1 | ALTER TABLE stuinfo MODIFY COLUMN seat INT UNIQUE; |
#②表级约束
1 | ALTER TABLE stuinfo ADD UNIQUE(seat); |
5.添加外键
1 | ALTER TABLE stuinfo ADD CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id); |
三、修改表时删除约束
1.删除非空约束
1 | ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NULL; |
2.删除默认约束,相当于又加了一遍的感觉
1 | ALTER TABLE stuinfo MODIFY COLUMN age INT ; |
3.删除主键
1 | ALTER TABLE stuinfo DROP PRIMARY KEY; |
4.删除唯一
1 | ALTER TABLE stuinfo DROP INDEX seat; |
5.删除外键
1 | ALTER TABLE stuinfo DROP FOREIGN KEY fk_stuinfo_major; |
标识列
又称为自增长列
含义:可以不用手动的插入值,系统提供默认的序列值
特点:
1、标识列必须和主键搭配吗?不一定,但要求是一个key
2、一个表可以有几个标识列?至多一个!
3、标识列的类型只能是数值型
4、标识列可以通过 SET auto_increment_increment=3;设置步长
可以通过 手动插入值,设置起始值
一、创建表时设置标识列
1 | DROP TABLE IF EXISTS tab_identity; |
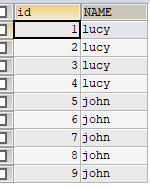
1 | TRUNCATE TABLE tab_identity; |
设置步长和起始值(MySQL不支持)
1 | SHOW VARIABLES LIKE '%auto_increment%'; |
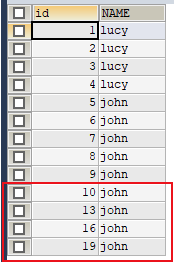
设置步长值为3:
1 | SET auto_increment_increment=3; |
TCL-Transaction Control Language 事务控制语言
事务:
一个或一组sql语句组成一个执行单元,这个执行单元要么全部执行,要么全部不执行。
案例:转账
张三丰 1000
郭襄 1000
存储引擎:
1、数据用不同的存储技术进行存储,也称为表类型;
2、通过show engines;来查看mysql支持的存储引擎
3、mysql主流的存储引擎是innodb、myisam、memory,但是后两者不支持事务;
update 表 set 张三丰的余额=500 where name=’张三丰’
意外
update 表 set 郭襄的余额=1500 where name=’郭襄’
事务的特性:
ACID
原子性:一个事务不可再分割,要么都执行要么都不执行
一致性:一个事务执行会使数据从一个一致状态切换到另外一个一致状态
隔离性:一个事务的执行不受其他事务的干扰
持久性:一个事务一旦提交,则会永久的改变数据库的数据.
事务的创建
隐式事务:事务没有明显的开启和结束的标记
比如insert、update、delete语句
delete from 表 where id =1;
但是很多时候,隐式事务不能够处理我们的问题,例如不能够同时执行这两条语句
update 表 set 张=500;
update 表 set 李=1500;
显式事务:事务具有明显的开启和结束的标记
前提:必须先设置自动提交功能为禁用
开启显示事务,只针对当前这一次有效:
1 | set autocommit=0; |
步骤1:开启事务
set autocommit=0;
start transaction;可选的(上面的可以不写,因为写了这句就代表开启了上面那句)
步骤2:编写事务中的sql语句(select insert update delete)像create drop Alter 没有事务之说;
语句1;
语句2;
…
步骤3:结束事务
commit;提交事务
rollback;回滚事务,单纯的MySQL是做不到的,必须结合应用程序来进行
1.演示事务的使用步骤
开启事务
1 | SET autocommit=0; |
编写一组事务的语句
1 | UPDATE account SET balance = 1000 WHERE username='张无忌'; |
结束事务,回滚和提交都可以
1 | ROLLBACK; |
1 | SELECT * FROM account; |
但你没有结束事务之前,文件的修改都保留在内存,只有进行了提交才真正的写到了硬盘
1. 事务的隔离级别
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| read uncommited | √ | √ | √ |
| read commited | × | √ | √ |
| repeatable read | × | × | √ |
| serializable | × | × | × |


脏读一般针对的是更新,例如update和rollback
不可重复读:也是对于更新,表示前后两次导致值不同
幻读:针对着是插入和删除,与脏读的相同点都是:没有提交,
mysql中默认 第三个隔离级别 repeatable read
oracle中默认第二个隔离级别 read committed查看当前的隔离级别:
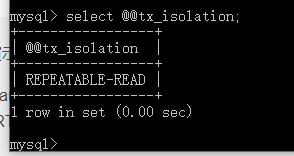
1.设置为最低的隔离级别——READ-UNCOMMITTED
set session transaction isolation level read uncommitted;
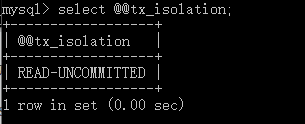
开启事物:
set autocommit=0;

1. 脏读演示:
左表还没有提交,右边就可以看到数据修改内容(将张无忌替换为了join)

数据回滚:rollback;
此时又将join变为了张无忌

这个数据也可以叫做不可重复数据,因为在这种情况下三种并发问题都可以出现:

2. 切换隔离级别为read committed;
避免了脏读,但是没有避免不可重复读
set session transaction isolation level read committed;
左边已经修改了数据,为”张飞“,以为没有提交,所以右边没有改变,没有出现脏读:

不可重复读:


总结:repeatable commited可以解决脏读但是解决不了,幻读和不可重复读
3. 切换隔离级别为repeatable read
set session transaction isolation level repeatable read;
解决了脏读(在未提交之前)和不可重复读(提交前后):

解决了提交事务查询才会变为刘备:

未解决幻读:幻读就是针对插入的
左边开启一个事务,右边执行了一个事务,在左边会发生一个莫名的变化(明明看到的是三行却有四行受到了影响):

4. 事物隔离级别为serializable;
set session transaction isolation level serializable;

2. 演示事务对于delete和truncate的处理的区别
delete可以成功回滚,truncate不支持回滚
1 | SET autocommit=0; |
3. 演示savepoint 的使用(有些像编程中的断点)
设置了SAVEPOINT a;#设置保存点,ROLLBACK TO a;#回滚到保存点,25删除了,因为rollback所以28又回来了
1 | SET autocommit=0; |
视图
含义:虚拟表,和普通表一样使用,比如:舞蹈班和普通班级的对比,舞蹈班是临时的,但是普通班是一直存在的
mysql5.1版本出现的新特性,是通过表动态生成的数据
视图的好处:
- 重用SQL语句;
- 简化了复杂的aql操作,不必知道查询细节;
保护数据,提高安全性;
创建语法的关键字 是否实际占用物理空间 使用
视图 create view 只是保存了sql逻辑 增删改查,只是一般不能增删改
表 create table 保存了数据 增删改查
| 创建语法的关键字 | 是否实际占用物理空间 | 使用 | |
|---|---|---|---|
| 视图 | create view | 没有(只是保存了逻辑) | 增删改查,一般不能增删改 |
| 表 | create table | 占用 | 增删改查 |
#案例:查询姓张的学生名和专业名
1 | SELECT stuname,majorname |
做成一个视图:
1 | CREATE VIEW v1 |
此时在查询就很方便了
1 | SELECT * FROM v1 WHERE stuname LIKE '张%'; |
一、创建视图
语法:
create view 视图名
as
查询语句;
USE myemployees;
1.查询姓名中包含a字符的员工名、部门名和工种信息
①创建
1 | CREATE VIEW myv1 |
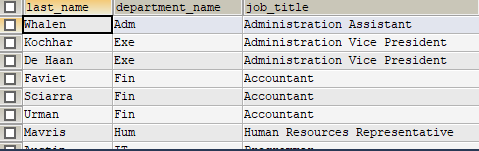
②使用
1 | SELECT * FROM myv1 WHERE last_name LIKE '%a%'; |
2.查询各部门的平均工资级别
①创建视图查看每个部门的平均工资,因为没有grade_level就没有生成结果
1 | CREATE VIEW myv2 |
②使用
1 | SELECT myv2.`ag`,g.grade_level |
3.查询平均工资最低的部门信息,升序排列,只选择第一个1
1 | SELECT * FROM myv2 ORDER BY ag LIMIT 1; |
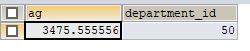
4.查询平均工资最低的部门名和工资
1 | CREATE VIEW myv3 |
1 | SELECT d.*,m.ag |

二、视图的修改
方式一:
create or replace view 视图名
as
查询语句;
1 | SELECT * FROM myv3; |
下面是修改语句,进行修改之后,再次查询,就发生了变化
1 | CREATE OR REPLACE VIEW myv3 |
方式二:
语法:
alter view 视图名
as
查询语句;
1 | ALTER VIEW myv3 |
三、删除视图
语法:drop view 视图名,视图名,…;
1 | DROP VIEW emp_v1,emp_v2,myv3; |
四、查看视图
DESC myv3;
SHOW CREATE VIEW myv3;

案例讲解
#一、创建视图emp_v1,要求查询电话号码以‘011’开头的员工姓名和工资、邮箱
1 | CREATE OR REPLACE VIEW emp_v1 |
#二、创建视图emp_v2,要求查询部门的最高工资高于12000的部门信息
1 | CREATE OR REPLACE VIEW emp_v2 |
1 | SELECT d.*,m.mx_dep |
五、视图的更新
1 | CREATE OR REPLACE VIEW myv1 |
1 | CREATE OR REPLACE VIEW myv1 |
1 | SELECT * FROM myv1; |
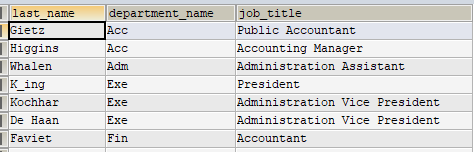
1.插入
1 | INSERT INTO myv1 VALUES('张飞','zf@qq.com'); |
2.修改
1 | UPDATE myv1 SET last_name = '张无忌' WHERE last_name='张飞'; |
3.删除
1 | DELETE FROM myv1 WHERE last_name = '张无忌'; |
具备以下特点的视图不允许更新
①包含以下关键字的sql语句:分组函数、distinct、group by、having、union或者union all
1 | CREATE OR REPLACE VIEW myv1 |
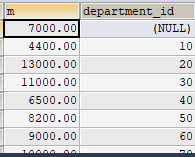
更新,不可以执行,因为包含GROUP BY:
1 | UPDATE myv1 SET m=9000 WHERE department_id=10; |
②常量视图
1 | CREATE OR REPLACE VIEW myv2 |
1 | SELECT * FROM myv2; |
更新,不可以执行,因为包含常量:
1 | UPDATE myv2 SET NAME='lucy'; |
③Select中包含子查询
1 | CREATE OR REPLACE VIEW myv3 |
更新
SELECT * FROM myv3;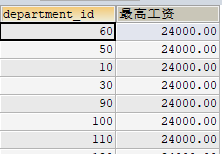
UPDATE myv3 SET 最高工资=100000;不可以
④join
1 | CREATE OR REPLACE VIEW myv4 |
更新,不可以执行,因为包含JOIN:
1 | SELECT * FROM myv4; |
⑤from一个不能更新的视图
1 | CREATE OR REPLACE VIEW myv5 |
更新,不可以执行,因为包含不可以更新的视图
1 | SELECT * FROM myv5; |
⑥where子句的子查询引用了from子句中的表
1 | CREATE OR REPLACE VIEW myv6 |
更新,不可以的
1 | SELECT * FROM myv6; |
测试题
创建book表,字段如下:
bid整型,要求主键
bname字符型,要求设置唯一键,并非空
price浮点型,要求有默认值10
bttyped 类型编号,要求引用booktype表的id字段
已知booktype表(不用创建),字段如下:
id,name
1 | CREATE TABLE book( |
2.开启事物
向表中插入1行数据,并结束
1 | set autocommit=0; |
3.创建视图,实现查询价格在90-120之间的书名和价格
1 | create view myv1 |
4.修改视图,实现查询价格在90-120之间的书名和价格
1 | create or replace view myv1 |
5.删除刚才建的视图
1 | drop view myv1; |
$$ —- \mathcal{End} —- $$

